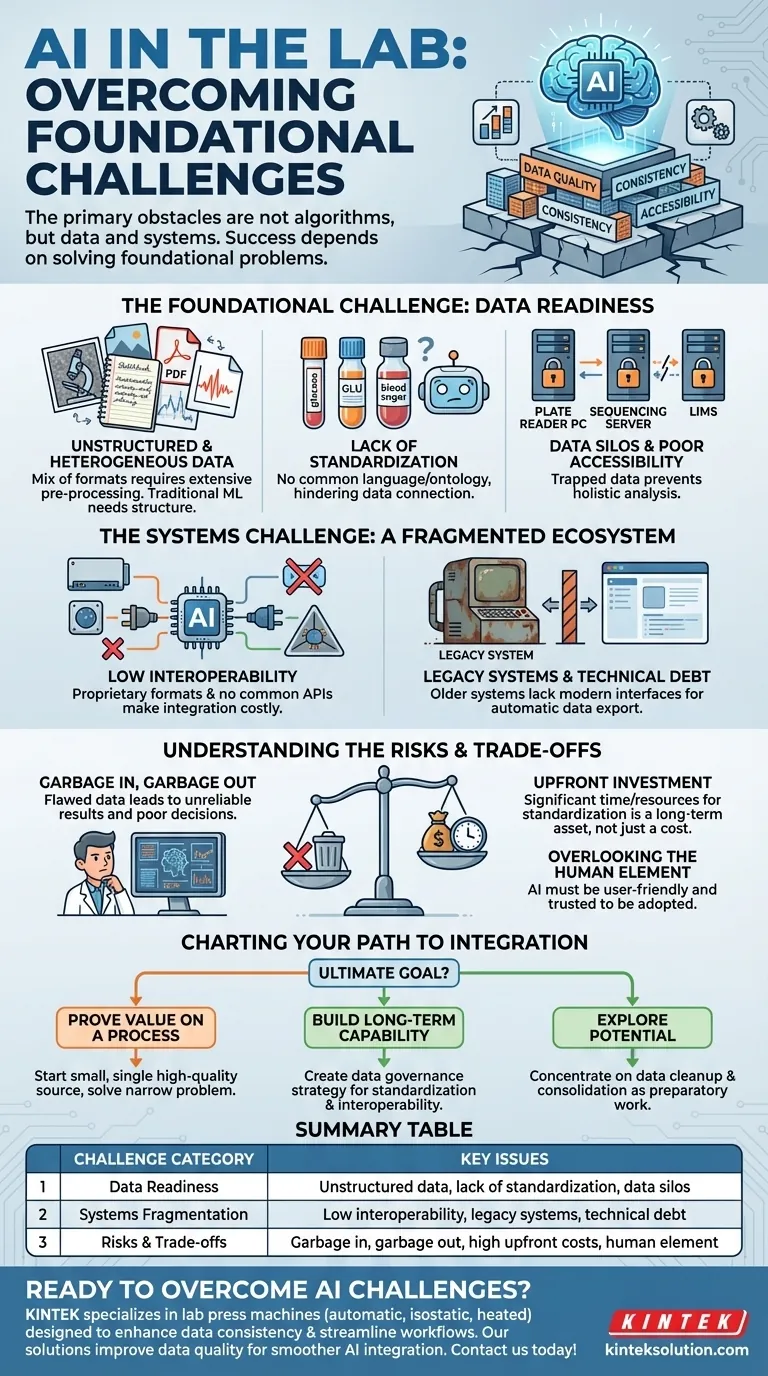
Les principaux obstacles à l'intégration de l'IA ne résident pas dans les algorithmes eux-mêmes, mais dans les données et les systèmes fondamentaux du laboratoire. Les défis les plus importants sont la gestion de vastes quantités de données non structurées, un manque généralisé de normalisation des données et la faible interopérabilité entre les différents instruments et logiciels de laboratoire.
Le succès de toute initiative d'IA en laboratoire est déterminé avant même que le premier algorithme ne soit exécuté. Il dépend presque entièrement de la résolution des problèmes fondamentaux de qualité, de cohérence et d'accessibilité des données.

Le défi fondamental : la préparation des données
Avant que l'IA ne puisse fournir des informations, elle a besoin de données propres, organisées et compréhensibles. Malheureusement, l'environnement de laboratoire typique est souvent l'opposé. Cet écart de préparation des données est le plus grand obstacle.
Données non structurées et hétérogènes
La plupart des données de laboratoire ne se présentent pas sous un format simple, semblable à un tableau. Elles existent sous forme d'images de microscopes, de texte dans des cahiers de laboratoire, de PDF de relevés d'instruments et de fichiers de signaux bruts provenant de divers appareils.
Les modèles d'IA, en particulier l'apprentissage automatique traditionnel, nécessitent des données structurées pour fonctionner efficacement. Les alimenter avec ce mélange de formats sans un prétraitement approfondi est une recette pour l'échec.
Manque de standardisation
Il n'y a souvent pas de norme unique et appliquée pour la façon dont les données sont nommées, formatées ou enregistrées. Un instrument peut étiqueter un échantillon "glucose", un autre "GLU", et un journal manuel peut l'appeler "sucre sanguin".
Sans un langage commun, ou une ontologie, une IA ne peut pas relier de manière fiable les points de données connexes à travers différentes expériences ou systèmes. Cette incohérence compromet fondamentalement sa capacité à avoir une vue d'ensemble complète.
Silos de données et faible accessibilité
Les données sont fréquemment piégées dans des systèmes isolés. La sortie d'un lecteur de plaques peut se trouver sur son PC dédié, tandis que les données de séquençage résident sur un serveur séparé, et les métadonnées des échantillons sont verrouillées dans un LIMS (système de gestion des informations de laboratoire).
Ces "silos de données" empêchent l'IA d'accéder et de corréler les informations provenant de différentes sources, ce qui est essentiel pour découvrir des modèles complexes.
Le défi des systèmes : un écosystème fragmenté
Le matériel et les logiciels qui génèrent les données de laboratoire sont rarement conçus pour fonctionner ensemble. Cette fragmentation crée une immense friction technique pour tout projet d'intégration d'IA.
Faible interopérabilité
Différents instruments, souvent de fournisseurs concurrents, utilisent des logiciels et des formats de données propriétaires qui ne communiquent pas entre eux. L'extraction de données nécessite souvent une exportation manuelle, des scripts personnalisés, ou est parfois impossible.
Ce manque de protocole de communication commun (comme une API) signifie que chaque nouvelle connexion entre un système et votre plateforme d'IA devient un projet d'intégration personnalisé et coûteux.
Systèmes hérités et dette technique
De nombreux laboratoires s'appuient sur des instruments ou des logiciels plus anciens qui ont été fiables pendant des années. Ces systèmes hérités n'ont jamais été conçus pour le monde centré sur les données et interconnecté que l'IA exige.
Ils manquent souvent des interfaces modernes nécessaires pour exporter automatiquement les données, créant ainsi une barrière importante. Les remplacer est coûteux, mais les contourner est complexe et fragile.
Comprendre les compromis et les risques
Ignorer ces défis fondamentaux et faire avancer un projet d'IA introduit un risque significatif et est la cause la plus fréquente d'échec.
Le risque du "Garbage In, Garbage Out"
C'est la règle cardinale de la science des données. Un modèle d'IA entraîné sur des données incohérentes, désordonnées ou incorrectes produira des résultats peu fiables et trompeurs.
Pire encore, cela peut créer un faux sentiment de confiance, conduisant à de mauvaises décisions scientifiques ou commerciales basées sur des prédictions d'IA erronées. Le modèle n'est pas le problème ; ce sont les données.
Le coût de l'investissement initial
Aborder correctement la standardisation des données et l'interopérabilité des systèmes nécessite un investissement initial important en temps, en ressources et en personnel. Il n'y a pas de raccourci.
Cependant, cet investissement ne doit pas être considéré comme un coût de l'IA, mais comme un atout à long terme. Une infrastructure de données propre et accessible bénéficie à tous les aspects du laboratoire, et pas seulement à un seul projet d'IA.
Négliger l'élément humain
Un outil d'IA n'est efficace que s'il est utilisé. Si le système est difficile à utiliser, ne s'intègre pas dans les flux de travail existants ou produit des résultats auxquels les scientifiques ne font pas confiance, il sera abandonné.
Une intégration réussie nécessite de se concentrer sur l'expérience de l'utilisateur final, en s'assurant que l'IA fournit des résultats clairs et explicables qui augmentent, plutôt que de perturber, le travail du scientifique.
Tracer votre chemin vers l'intégration de l'IA
Votre stratégie pour la mise en œuvre de l'IA doit être dictée par votre objectif ultime. Le bon premier pas dépend de l'ampleur de votre ambition.
- Si votre objectif principal est de prouver la valeur d'un processus spécifique : commencez petit avec une seule source de données de haute qualité et résolvez un problème étroit et bien défini.
- Si votre objectif principal est de construire une capacité d'IA à long terme à l'échelle du laboratoire : Votre premier projet doit être la création d'une stratégie de gouvernance des données qui aborde de front la normalisation et l'interopérabilité.
- Si votre objectif principal est simplement d'explorer le potentiel de l'IA : concentrez-vous sur le nettoyage et la consolidation des données, car c'est le travail préparatoire le plus précieux et le plus nécessaire pour toute future entreprise d'IA.
En fin de compte, préparer votre laboratoire à l'IA consiste à construire une base solide de données propres, connectées et accessibles.
Tableau récapitulatif :
| Catégorie de défi | Problèmes clés |
|---|---|
| Préparation des données | Données non structurées, manque de normalisation, silos de données |
| Fragmentation des systèmes | Faible interopérabilité, systèmes hérités, dette technique |
| Risques et compromis | Garbage in, garbage out, coûts initiaux élevés, élément humain |
Prêt à surmonter les défis de l'intégration de l'IA dans votre laboratoire ? KINTEK est spécialisé dans les presses de laboratoire, y compris les presses de laboratoire automatiques, les presses isostatiques et les presses de laboratoire chauffantes, conçues pour améliorer la cohérence des données et rationaliser les flux de travail pour les laboratoires. Nos solutions aident à améliorer la qualité des données et l'interopérabilité des systèmes, rendant l'intégration de l'IA plus fluide et plus efficace. Contactez-nous dès aujourd'hui pour découvrir comment nous pouvons soutenir les besoins de votre laboratoire et stimuler l'innovation !
Guide Visuel