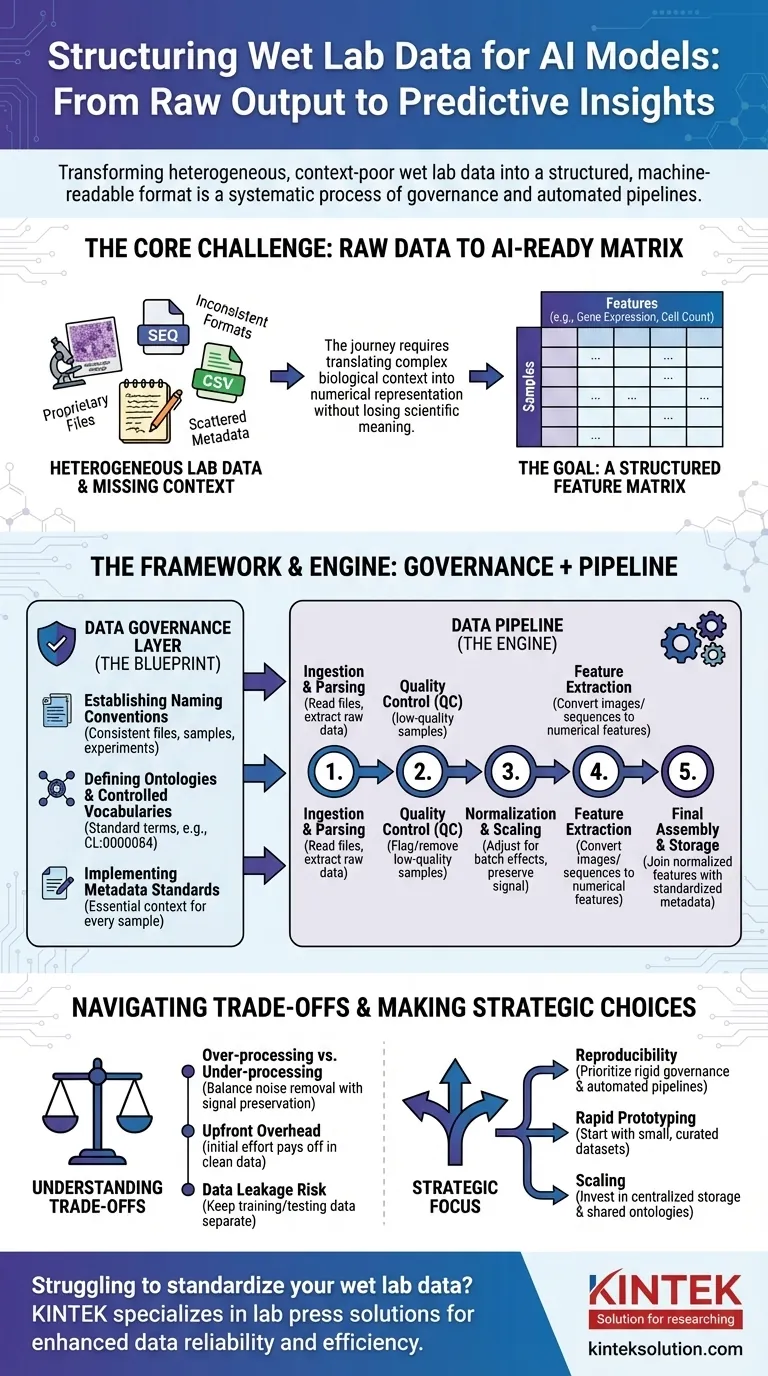
Pour préparer les données de laboratoire humide à l'IA, vous devez les transformer de leur état brut, souvent incohérent, en un format structuré et lisible par machine. Il ne s'agit pas d'une seule étape, mais d'un processus systématique impliquant la gouvernance des données pour créer des règles claires, suivi de pipelines de données qui automatisent le nettoyage, la normalisation et la structuration des résultats expérimentaux bruts dans un format cohérent, adapté à l'entraînement des modèles.
Le principal défi n'est pas simplement de reformater les fichiers. Il s'agit de traduire systématiquement un contexte biologique complexe — tel que les conditions expérimentales, l'historique des échantillons et les techniques de mesure — en une représentation numérique structurée à partir de laquelle un modèle d'IA peut apprendre sans perdre de signification scientifique critique.

Le problème fondamental : des données brutes aux données prêtes pour l'IA
Le cheminement du paillasse de laboratoire à un modèle prédictif est semé d'embûches en matière de données. Les données brutes issues des instruments scientifiques sont rarement, voire jamais, prêtes à être utilisées directement dans un algorithme d'IA.
L'hétérogénéité des données de laboratoire
Les données de laboratoire humide se présentent sous une vaste gamme de formats. Cela inclut tout, des fichiers propriétaires des séquenceurs et microscopes aux simples CSV des lecteurs de plaques, chacun avec sa propre structure et ses particularités.
Un modèle d'IA, cependant, nécessite un format unifié.
La malédiction du contexte manquant
Les informations critiques, ou métadonnées, sont souvent dispersées. Elles peuvent se trouver dans le carnet d'un scientifique, une feuille de calcul séparée, ou simplement dans sa tête. Sans ce contexte (par exemple, quel médicament a été appliqué, la température, la lignée cellulaire utilisée), les données numériques n'ont aucun sens.
L'objectif : une matrice de caractéristiques
En fin de compte, la plupart des modèles d'IA ont besoin de données sous forme de matrice de caractéristiques. Il s'agit d'un simple tableau où les lignes représentent des échantillons individuels (par exemple, un patient, un puits de culture cellulaire) et les colonnes représentent des caractéristiques (par exemple, les niveaux d'expression génique, les mesures de morphologie cellulaire, les concentrations de protéines).
Un cadre de normalisation : la couche de gouvernance des données
Avant de pouvoir construire des pipelines automatisés, vous devez établir des règles. C'est la gouvernance des données — le plan qui assure la cohérence entre toutes les expériences et toutes les équipes. C'est l'étape la plus critique et souvent négligée.
Établir des conventions de nommage
Une règle simple mais puissante est d'imposer un schéma de nommage cohérent pour les fichiers, les échantillons et les expériences. Cela permet de lier et de suivre les données de manière programmatique, de leur origine à l'analyse finale.
Définir des ontologies et des vocabulaires contrôlés
Une ontologie fournit un ensemble standard de termes pour décrire les entités biologiques. Par exemple, au lieu d'autoriser "cellule T", "lymphocyte T" et "Tcell", un vocabulaire contrôlé impose un seul terme, comme CL:0000084 de l'Ontologie cellulaire.
Ceci évite l'ambiguïté et garantit que les données de différentes expériences sont véritablement comparables.
Mettre en œuvre des normes de métadonnées
Vous devez définir les métadonnées minimales qui doivent être capturées pour chaque échantillon. Cela inclut souvent la source de l'échantillon, les conditions expérimentales, les réglages de l'instrument et la date. Cette règle garantit qu'aucun point de donnée ne devient orphelin, détaché de son contexte.
Le moteur de la transformation : construire le pipeline de données
Une fois les règles de gouvernance établies, vous pouvez construire un pipeline de données. Il s'agit d'une série d'étapes logicielles automatisées qui transforment les données brutes en la matrice de caractéristiques finale prête pour l'IA.
Étape 1 : Ingestion et analyse des données
La première tâche du pipeline est de trouver et de lire les fichiers de données brutes. Cette étape implique l'écriture d'analyseurs spécifiques pour le format de sortie de chaque instrument afin d'extraire les mesures primaires et toutes les métadonnées associées.
Étape 2 : Contrôle Qualité (CQ)
Toutes les données ne sont pas de bonnes données. Le pipeline doit automatiquement signaler ou supprimer les échantillons de mauvaise qualité basés sur des métriques prédéfinies, telles qu'un faible nombre de cellules dans une expérience d'imagerie ou une mauvaise qualité de lecture d'un séquenceur.
Étape 3 : Normalisation et mise à l'échelle
Les mesures provenant de différents lots ou plaques présentent souvent des variations techniques. La normalisation est une étape cruciale qui ajuste les données pour rendre les mesures comparables entre les expériences, en supprimant le bruit technique tout en préservant le signal biologique.
Étape 4 : Extraction de caractéristiques
Les données brutes ne sont souvent pas au format de caractéristiques. Une image, par exemple, doit être traitée pour en extraire des caractéristiques numériques telles que la taille, la forme et l'intensité des cellules. Une séquence d'ADN peut être convertie en un vecteur de fréquence de k-mer. Cette étape transforme les données complexes en chiffres que l'IA peut utiliser.
Étape 5 : Assemblage final et stockage
Enfin, le pipeline joint les caractéristiques normalisées aux métadonnées standardisées. Cela crée la matrice de caractéristiques finale et propre, qui est ensuite enregistrée dans un format stable et interrogeable (comme Parquet ou une base de données) pour l'entraînement du modèle.
Comprendre les compromis
La structuration des données n'est pas un processus neutre. Chaque choix que vous faites peut influencer la performance et l'interprétation finales du modèle.
Sur-traitement vs Sous-traitement
Une normalisation ou un filtrage agressif peuvent parfois supprimer des signaux biologiques subtils mais importants. Inversement, ne pas supprimer le bruit technique garantira que votre modèle apprendra des artefacts expérimentaux au lieu de la biologie. C'est un équilibre constant.
La standardisation engendre des frais généraux initiaux
La mise en œuvre de la gouvernance des données exige un effort initial et une adhésion importants de toute l'équipe. Cela peut sembler ralentir la recherche au début, mais cela rapporte d'énormes dividendes en évitant des mois de travail de nettoyage plus tard.
Le danger de la fuite de données
Une fonction critique du pipeline est de maintenir les données d'entraînement et de test séparées. Si des informations du jeu de test (par exemple, sa distribution globale) sont utilisées pour normaliser le jeu d'entraînement, la performance de votre modèle sera artificiellement gonflée et il échouera dans le monde réel.
Faire le bon choix pour votre objectif
Votre approche de la structuration des données doit être guidée par votre objectif final.
- Si votre objectif principal est la reproductibilité : Donnez la priorité à une gouvernance des données rigide et à des pipelines entièrement automatisés et contrôlés par version dès le premier jour.
- Si votre objectif principal est le prototypage rapide : Commencez par un petit ensemble de données organisé manuellement pour valider votre approche IA avant d'investir dans un pipeline à grande échelle.
- Si votre objectif principal est la mise à l'échelle au sein d'une grande organisation : Investissez massivement dans le stockage centralisé des données, les ontologies partagées et les composants de pipeline communs pour éviter les silos de données.
En fin de compte, traiter vos données avec la même rigueur que vos expériences de laboratoire humide est le fondement de la construction d'une IA biologique réussie et fiable.
Tableau récapitulatif :
| Étape | Action clé | Objectif |
|---|---|---|
| Gouvernance des données | Établir des conventions de nommage, des ontologies, des normes de métadonnées | Assurer la cohérence et la comparabilité entre les expériences |
| Pipeline de données | Ingérer, analyser, contrôler la qualité, normaliser, extraire les caractéristiques, assembler | Automatiser la transformation des données brutes en une matrice de caractéristiques prête pour l'IA |
| Compromis | Équilibrer le sur-traitement et le sous-traitement, gérer les frais généraux | Optimiser les performances du modèle et éviter les fuites de données |
Vous avez du mal à standardiser vos données de laboratoire humide pour l'IA ? KINTEK est spécialisé dans les presses de laboratoire, y compris les presses de laboratoire automatiques, les presses isostatiques et les presses de laboratoire chauffées, aidant les laboratoires à améliorer la fiabilité des données et l'efficacité expérimentale. Laissez-nous vous aider à obtenir des résultats cohérents — contactez-nous dès aujourd'hui pour discuter de vos besoins et découvrir comment nos solutions peuvent soutenir votre recherche axée sur l'IA !
Guide Visuel